How to Keep 1.6 Million Podcasts Up to Date
Roughly two and a half years ago, we started into the journey of building a podcasting platform that delivers own content as well as providing a lot of known and publically available podcasts. It was called FYEO. Unfortunately, we had to shut down the platform last year. But I still want to share some learnings.

In the two years or so thousands of podcasts have been added to the main libraries like Apple Podcasts, Spotify and others.
The FYEO database held around 1.6 million podcasts at its peak. Each one of those podcasts does have quite a number of episodes which contain the real contents users are interested in: the audio track. And this is the stuff that every podcast platform wants to display to their customers. As soon as it comes out, is published. And as soon as people are searching for it.
Let me take you on the journey of building the system that helped us make sure we have all the data in place to show the latest episodes to our customers.
Preconditions
There are a couple of things you need to know before digging into our approach:
- All podcasts publish meta-data via a web feed which can be read by platforms like Apple Podcasts or others to get the latest information from these podcasts, including the published episodes.
- Audio files for podcasts are hosted with a podcaster's hosting service and should always be streamed from there, reason being a) to prevent load on the podcasting platform's end, b) to allow statistics to be collected, and c) to include dynamic content like ads.
Some podcasts update their data each day, maybe even twice. Others only once per months. And some even don't publish contents for a year or more. This will be of relevance later on.
The Objective
Our main goal is to keep all podcasts in the database up to date, which means we have the latest episode available on the platform as soon as it is published. The main scenario being a new episode comes out, a podcaster tweets about it, and people start searching for it in our library.
Underlying, more technical, objectives:
- Make it possible to update all relevant podcasts fast
- Allow the update mechanism to be extensible with actions that need to run asynchronously, like picking colors from an image
- Be conservative with the usage of computing resources
- Keep the software components with as little logic as possible
Solution finding
The Easy Way: Push
I hear you saying, "Ok, let's implement some API where publishers can push their updates to and write them into the database. Done!" Yes, you are right. Using a push mechanism to get the latest updates is surely the easiest way to get the job done.
Unfortunately, the distributed world of podcast publishers does not work this way - no one will implement a webhook to your dedicated database when they publish a new episode. And this is fair.
When you look at Spotify or Google Podcasts, they have somewhat of a market power, you could argue. But still they do not implement the solution as a push mechanism - because the podcasting universe is decentralized and works well without these platforms… so, there is no need for it.
We need to turn to another solution.
Journey
The initial thoughts about how the architecture of this might work came when we started the development of FYEO. Getting the solution in place was a long journey, and we improved it over time. Good software solutions take time, I guess.
Initially, we thought about having exactly one crawler that calls all podcasts once per day. Turns out, crawling podcasts once per day is not enough to have the most relevant podcasts available with their latest episodes. Some podcasts even publish multiple times a day. And apparently not all podcasts are publishing at the same time.
Throughout our journey we started to learn about how podcasts get published, how data needs to be updated in our database and made available for users to search in the apps.
In general, the flow of one podcast to crawl looks like this: Request Feed > Check if there are any updates > Write to the database.
Here it's visualized, a bit easier to understand:
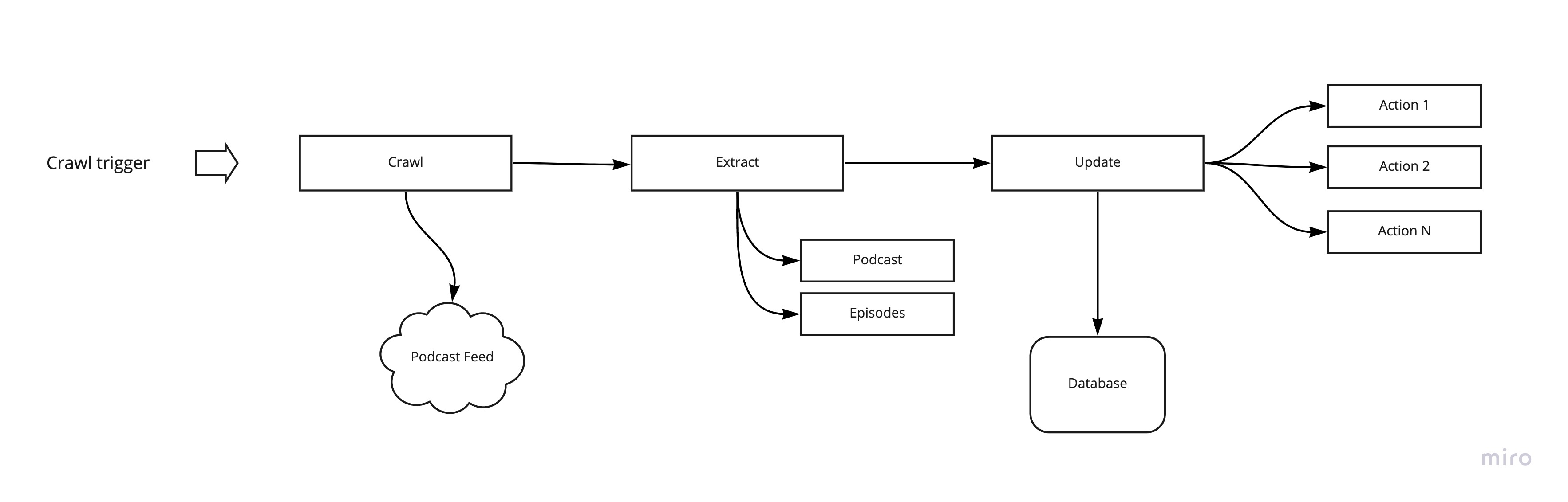
It turns out that this is only the peak of what needs to be done, so let's break it down a bit further:
- Request Feed: Crawl the feed by requesting the Feed URL that you need to acquire beforehand; make sure to have a failover in place if feed is not reachable; or mark podcast for deletion if it's not available for some time
- Parse Feed: From RSS to JavaScript object (we used RSS parser for this task)
- Normalize data: Entities of podcasts and episodes need to be normalized: updating URLs, internal IDs, matching categories, parsing texts
- Update Podcast Data: Make sure to know the existing podcast and compare both, if need be, write it to the database
- Update Episode Data: Same as with podcasts, also deletion of episodes needs to be handled
We also had several actions in place that occur after an update is written to the database, like syncing to our search system or updating meta-data for marketing purposes. This step allows for high extensibility.
Problems Crawling Lots of Podcasts
Along this way, we ran into a couple of challenges that were not trivial to solve. A selection:
Update the Right Podcast at the Right Time
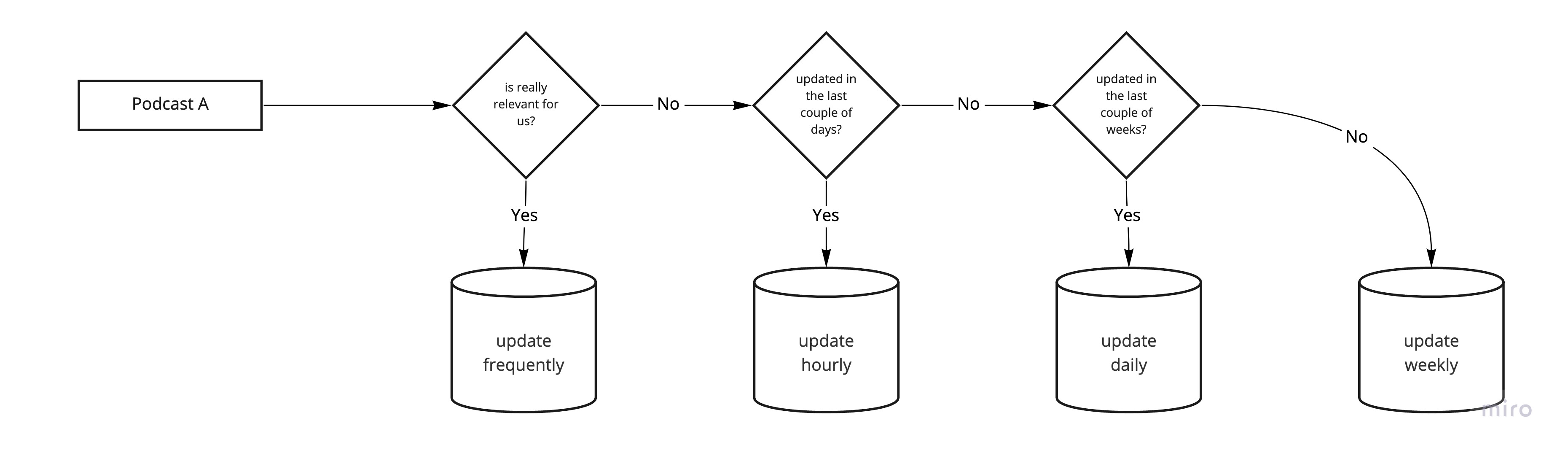
Figuring out when to crawl which podcast was the main challenge. Finding a working solution for this took us some time, and we decided to move forward with a kind of "bucket-solution": Podcasts that update frequently get crawled more often than podcasts that have not been updated in the last six months or so, podcasts that people listen to are even more relevant to be crawled.
Defining various metrics as identifiers for the crawl frequency of a podcast helped immensely to make sure the relevant podcasts were up-to-date.
Unique IDs for Episodes
The way how episodes inside an RSS feed are organized is that they hold an attribute called guid on an <item> element which is generally seen as the ID of the episode. Unfortunately, this GUID only is unique for one given podcast. This means you need to generate a UUID for an episode based on the podcast identifier combined with the GUID.
Interestingly enough, some podcast publishers update the GUIDs of an episode with every change of the feed. This results in some issues when updating the episodes in the database. Especially if you generate new UUIDs for these episodes (which is logically like this since the GUID is "new" to your system) and thus users will lose their favorites, listening status and more.
Working Around a Missing Official Specification
There is no official RSS feed specification for podcasts. This was a challenge from the beginning since podcast publishers use a variety of fields to publish data which needs to be normalized. Often times we would find out about certain ways on how data was published by analyzing our error logs.
A huge help here is the Apple Podcasts RSS feed requirements since most publishers are optimizing for it.
Coping with Database Load
For us, it was important to be conservative with spending for our infrastructure. Therefore, we optimized where ever we could when it came to read or write requests to our database.
Our architectural approach using event carried state in an event driven system allowed us to save immensely on read requests. Apart from that, we made sure the data we wrote to the database really changed. Everything that was not new was discarded.
Conclusion
We have spent a long time to figure out how we update podcasts in this way. It is pretty difficult. The journey was fun and we learned a lot.
Still, today I would start of differently. There have been so many ideas by knowledgeable people, we learned so many things along the way, and surely there are more "intelligent" ways on how to solve certain problems. I have heard people say, "Ha, that's not a real challenge to keep these 1.6 million podcasts up to date". I would challenge this - let's discuss it.
So, if you are about to build a crawling service for podcasts, I hope this article helps.
Hit me up on Twitter if you would like to discuss the ideas: @drublic.